
Complete Guide on Deep Learning Architectures Part 2: Autoencoders
Autoencoder: Basic Ideas
Autoencoder is the type of a neural network that reconstructs an input from the output. The basic idea here is that we have our inputs, and we compress those inputs in such a manner that we have the most important features to reconstruct it back.
As humans, when we’re asked to draw a tree with the least number of touches to the paper, (given that we’ve seen so many trees in our lifetime) we draw a line for the tree and couple of branches on top to provide an abstraction to how trees look like, this is what’s being done with autoencoder.

An average autoencoder looks like below:

Let’s take a solid case for image reconstruction.
We have our input layer with 784 units (assuming we give 28x28 images) and we could simply stack a layer on top with 28 units, and our output layer will have 784 units again.
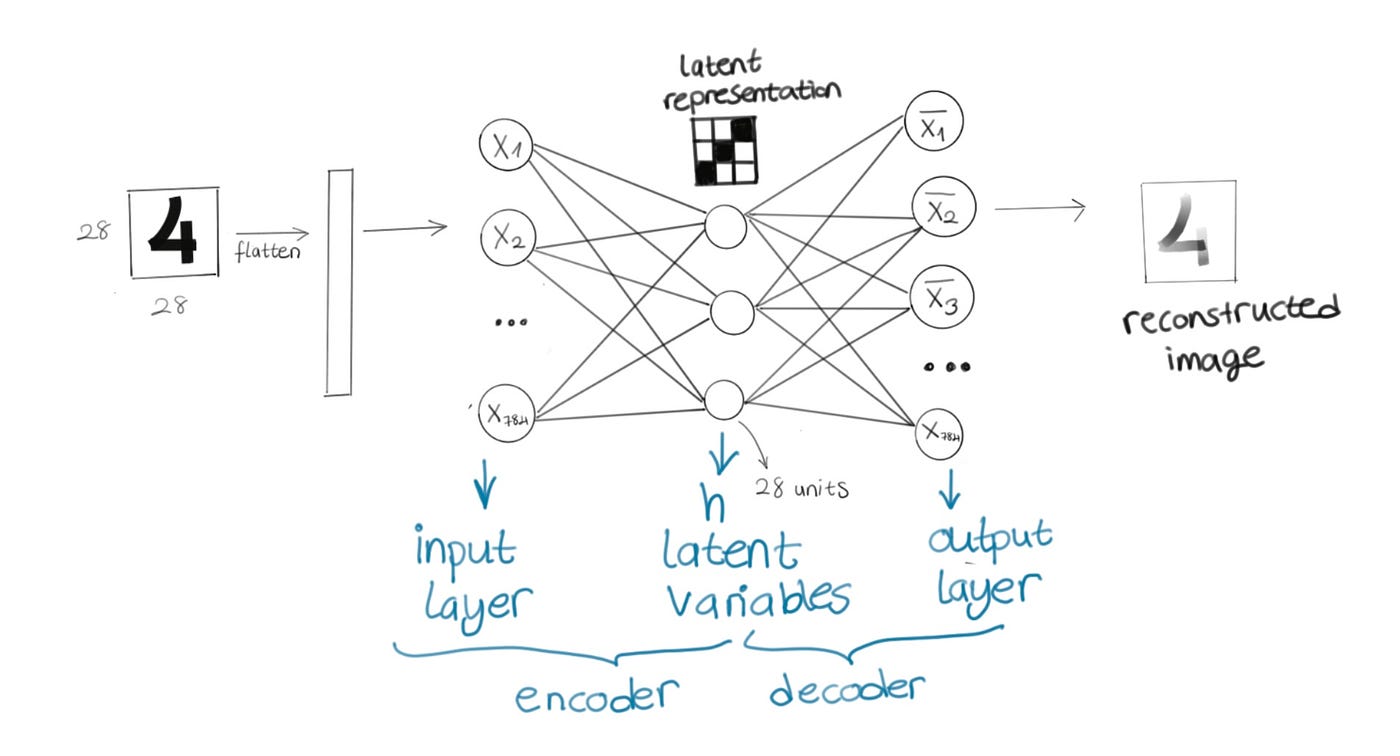
The first part is called “encoder” it encodes our inputs as latent variables, and second part is called “decoder” it will reconstruct our inputs from the latent variables.
The hidden layer having less number of units will be enough to do the compression and get latent variables. This is called “undercomplete autoencoder” (we also have other types of autoencoders but this gives the main idea, we’ll go over them as well). So in short, it’s just another feed forward neural network that has the following characteristics:
- input layer, hidden layer with less number of units and output layer
- it’s unsupervised: we will pass our inputs, get the output and compare with input again
- Our loss function will be comparing the input to compressed and then reconstructed version of the input and see if the model is successful or not.

- An autoencoder that has a decoder with a linear layer essentially does the same thing as principal component analysis (even though training objective is to copy the input).
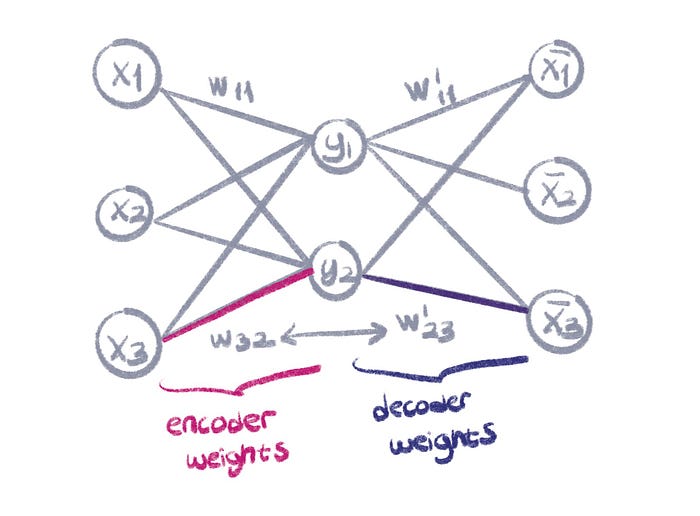
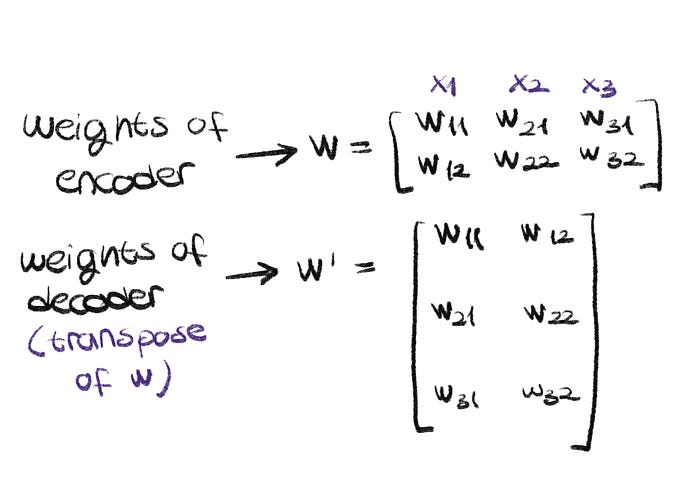
- Another core concept of autoencoder is weight tying. The weights of decoder are tied to weights of encoder. When you transpose the weight matrix of encoder, you get the weights of decoder. It’s a common practice for decoder weights to be tied to encoder weights. This saves memory (using less parameters), and reduced overfitting. I tried to explain my intuition below in multiple graphics. Let’s take a look.
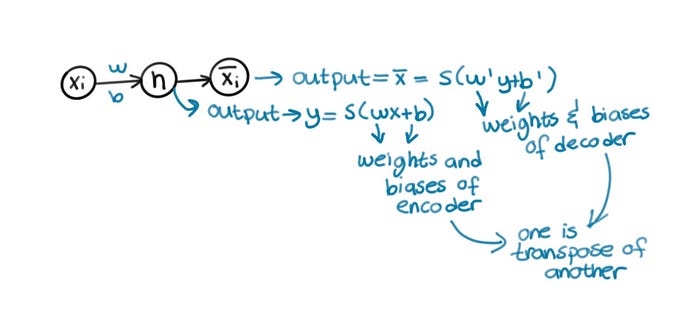
For the autoencoder below:
Weight matrix of encoder and decoder looks like this (you can skip this if you know what transpose means):
Keras Implementation
Let’s implement above network using Keras Subclassing API. I left comments for each layer to walk you through how to create it.
class Autoencoder(Model):
def __init__(self, latent_dim):
super(Autoencoder, self).__init__()
self.latent_dim = latent_dim
# define our encoder and decoder with Sequential API
# flatten the image and pass to latent layer to encode
self.encoder = tf.keras.Sequential([
layers.Flatten(),
layers.Dense(latent_dim, activation=’relu’),
])
# reconstruct latent outputs with another dense layer
# reshape back to image size
self.decoder = tf.keras.Sequential([
layers.Dense(784, activation=’sigmoid’),
layers.Reshape((28, 28))
])
# give input to encoder and pass encoder outputs (latents) to decoder
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
# initialize model with latent dimension of 128
autoencoder = Autoencoder(128)
# we can use simple MSE loss to compare input with reconstruction
autoencoder.compile(optimizer=’adam’, loss=losses.MeanSquaredError())
# we don’t have a y_train given we want output to be same as input :)
autoencoder.fit(x_train, x_train,
epochs=10,
shuffle=True,
validation_data=(x_test, x_test))In contrast to undercomplete autoencoder, complete autoencoder has equal units, and overcomplete autoencoder has more units in latent dimension compared to encoder and deocder. This causes the model to not learn anything but rather overfit. In undercomplete autoencoders on the other hand, the encoder and decoder might be overcapacitated with information if hidden layer is too small. To avoid overengineering this and add more functionalities to autoencoders, regularized autoencoders are introduced. These models have different loss functions that not only copy input to output, but make the model more robust to noisy, sparse or missing data. There are two types of regularized autoencoders, called denoising autoencoder and sparse autoencoder. We will not go through them in depth in this post since implementation doesn’t differ a lot from the normal autoencoder.
Sparse Autoencoder
Sparse autoencoders are autoencoders that have loss functions with a penalty for latent dimension (added to encoder output) on top of the reconstruction loss. These sparse features can be used to make the problem supervised, where the outputs depend on those features. This way, autoencoders can be used for problems like classification.

Denoising Autoencoder
Denoising autoencoders are type of autoencoders that remove the noise from a given input. To do this, we simply train the autoencoder with corrupted version of input with a noise and ask the model to output the original version of the input that doesn’t have the noise. You can see the comparison of loss functions below. The implementation of this is same as normal autoencoder, except for the input.

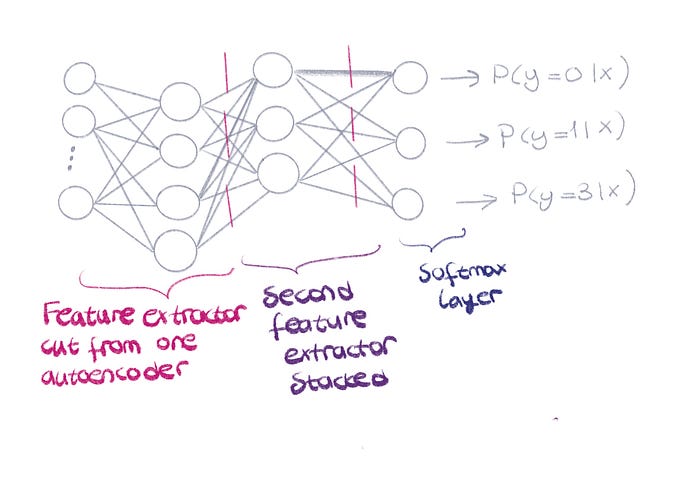
Stacked Autoencoder
Before ReLU existed, vanishing gradients would make it impossible to train deep neural networks. For this, stacked autoencoders were created as a hacky workaround. One autoencoder was trained to learn the features of the training data, and then the decoder layer was cut and another encoder is added on top and the new network is trained. At the end, softmax layer was added to use these features for classification. This could be one of the early techniques to do transfer learning.
There are variational autoencoders and other types heavily used in generative AI. I will go through them in another blog post. Thanks a lot if you’ve read this far and let me know if there’s anything I can improve :)
