
Bir Veri Bilimcinin Araç Çantası
Merhabalar, bu blog yazımda kendimce kaggle yarışmaları ve şirketlerde gördüğüm veri bilimcilerin kullandığı ve benim de çok sevdiğim araçları derledim. Bu yazı fazlasıyla önyargılı (opinionated) bir yazı, bunu belirtmekte fayda var. Bunlar dışında olmasını düşündüğünüz araçlar varsa yazabilirsiniz.
Ben bu yazıda sklearn, fast.ai, TensorFlow ve PyTorch’u dışarıda bıraktım, bunlar zaten bilmeniz gereken kütüphaneler. Aynı şekilde hangi alanda çalışıyorsanız o alanın kendine has araçları var, bunlardan da bahsetmeyeceğim. (bilgisayarlı görü için opencv, NLP için spaCy, NLTK gibi)
Genel hatlarıyla ele alacak olursak sizi bir adım öteye taşıyacak araçlar ise,
- MLOps platformları (W&B, Comet ve diğerleri)
- Öneğitimli modeller barındıran çözümler (Hugging Face, AllenNLP, Stanza, Tensorflow Hub)
- Veri bilimi ve makine öğrenmesi projelerinize kolayca arayüz yapmanızı sağlayan kütüphaneler (Streamlit, Gradio)
- Size iyi bir baz çözüm veren AutoML araçları (H2O, AutoNLP)
Bunların hepsini az sonra detaylandıracağım.
Bu yazımda son bir senedir makine öğrenmesi mühendisi olarak çalıştığım yerde backend geliştirirken kullandığım postman, ngrok, gazpacho gibi araçlardan ve katıldığım açık kaynak sprint’lerde öğrendiğim flake8, black gibi kütüphanelerden de bahsettim, ilginizi çekebilir. Bunların hepsi hakkında video çekmeye başladım, yakında koymayı planlıyorum.
Hazırsak başlayalım.
MLOps Platformları
MLOps, DevOps’un kod odaklı değil model odaklı yönetim biçimi. MLOps’ta kodun versiyon kontrolünden ziyade deney takibi (experiment tracking) var. Hangi modeliniz, hangi hiperparametrelerle nasıl sonuç verdi bunlara bakıyorsunuz aslında. Makine öğrenmesinin baştan sona kendine has dertleri var, başka bir tanesi ise veri kayması (data drift), bunu da üretim sonrasında modeli izleyen bir araçla halletmeniz gerek, bu platformlar bu çözümü de sağlıyor. Bunlardan en çok bilinen iki tanesi Weights & Biases ve Comet. Bu araçlar çok büyük veri bilimi takımları tarafından an itibariyle kullanılıyor. Bu linkte bu platformların karşılaştırmasına bakabilirsiniz (içinde MLFlow, KubeFlow, neptune.ai gibi diğer platformlar da var). Benim gözlemim Comet uçtan uca daha fazla süreci kendi içinde barındırıyor, W&B kaggle topluluklarında çokça kullanılıyor (belki UX farklılıklarından). Bunlar kişisel projeler için ücretsiz, bu yüzden kaggle yarışmalarında çok kullanılıyor, Google, OpenAI gibi şirketlerden para kazanıyorlar.
Öneğitimli Modeller Barındıran Platformlar
Makine öğrenmesi en son haliyle artık öneğitimli modellerin yaygın şekilde kullandığı bir paradigmaya kaydı. Öneğitimli modellerin hassas ayar çekilmesi, sıfırdan eğitime göre daha iyi performans sergiliyor. Bunun için Hugging Face, AllenNLP, TensorFlow Hub gibi platformları/kütüphaneleri iyi kullanmanız gerek. HuggingFace kendi içerisinde AllenNLP entegrasyonu yaptı, aynı zamanda facebook, google gibi şirketlerin veri bilimi takımları da modellerini Hugging Face’te barındırıyor. Bu platformlardan seçtiğiniz modeli alıp direkt kendi ağırlıklarıyla kullanabilir, ya da kendi veriniz üstünde hassas ayar yapabilirsiniz. Bu platformlarda veri setleri ve önişleme araçları da bulunuyor. Hugging Face ve TF Hub’da NLP’nin yanında ses modelleri/veri setleri ve görüntü modelleri/veri setleri de var. Eğer ses için özelleşmiş bir platform isterseniz Coqui’ye biz göz atmanızı öneririm.
Demo için Arayüz Oluşturma Kütüphaneleri
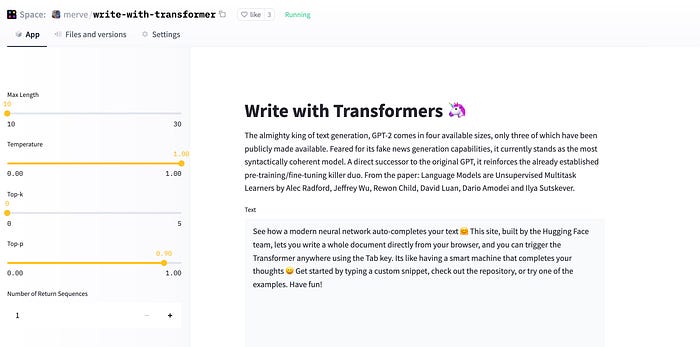
Veri bilimci ya da makine öğrenmesi mühendisiyseniz müşterilerinize ya da projedeki paydaşlarınıza model, keşifsel veri analizi, verisetleriniz gibi normalde notebook’larda dağınık şekilde gösterilen çalışmalarınıza arayüz yapmanız gerek, bu da eğer çok iyi bir önyüz geliştiricisi değilseniz zor bir iş. Burada imdadımıza streamlit ve gradio gibi kütüphaneler yetişiyor. Bunlar modellerinizle tahminde bulunmak için hiperparametreleri alan bileşenlerin yanısıra interaktif veri görselleştirme paketleri, çalıştığınız alan odaklı paketler (spacy-streamlit gibi) de barındırıyor. İkisini de kullanmış biri olarak görüşüm şu şekilde: eğer hızlıca makine öğrenmesi modelinizi demo haline getirmek isterseniz Gradio kullanın. Gradio daha çok model odaklı olmakla birlikte modeller için farklı çeşitlerde input’lar da alıyor (en son çizim için whiteboard bile getirmişlerdi). Streamlit’te ise streamlit’in çekirdek kütüphanesi dışında ekstra bir bileşen isterseniz bunları indirmeniz gerek. Aşağıda çok sevdiğim GPT-2 ile metin yazma uygulamasını streamlit’le yeniden oluşturdum.
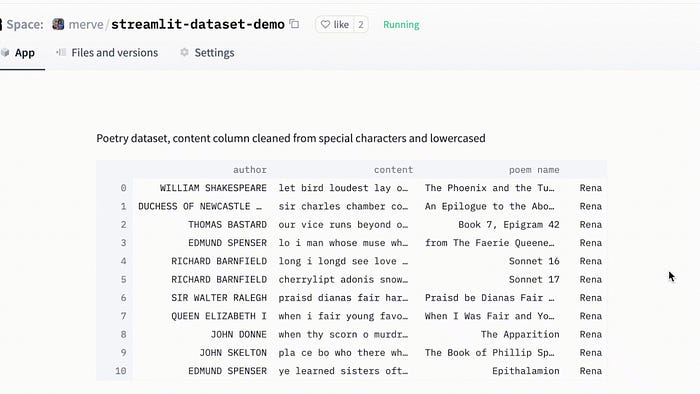
Aşağıda keşifsel veri analizimi streamlit’le arayüze çevirdim.
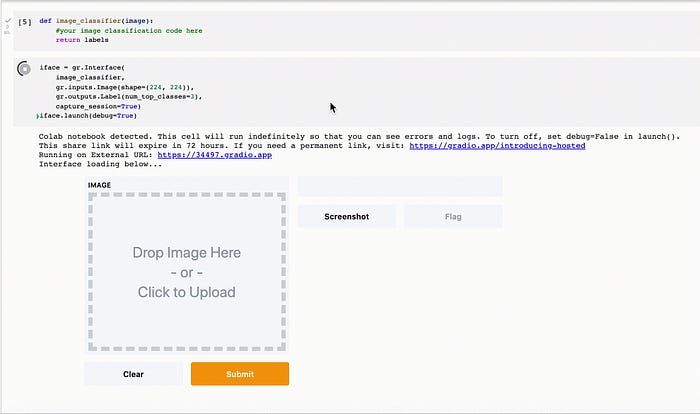
Gradio’da bir modeli alıp arayüz oluşturup paylaşılabilir hale getirmek iste 5 satırlık kod, üç dakika sürüyor.
Bunları nasıl yapabileceğinizi şurada Streamlit ve Gradio için ayrı ayrı blog’larda ele aldım, bunların kodları da blog’larda mevcut.
AutoML Araçları
AutoML çoğu zaman sihirli bir çözüm gibi algılansa da aslında makine öğrenmesi mühendisinin takım çantasında olması gereken araçlardan biri. Bu araçlar üzerine iyileştirme yapabileceğiniz temel bir çözüm sağlıyor aslında. İki tane AutoML mühendisiyle podcast yaptım, AutoML neler yapabilir neler yapamaz kendilerine sordum, aşağı yukarı aynı cevaplar aldım. Bu platformların çoğu şirketler için ücretli çözümler olarak veriliyor çünkü modellerinizi eğitip içinde hiperparametre optimizasyonu yapıyorlar, bu da çok uzun GPU saatleri ve yüksek maliyetler demek, bildiğim kadarıyla kişisel kullanım için ücretsiz planları da var. Bunların arkasında yatan arama algoritmalarını yazmak da ustalık gerektiriyor, kişisel görüşüm açık kaynak AutoML araçlarının (TPOT gibi) yeterince iyi çalışmadığı (bu örnekte arkada genetik algoritma çalışıyor, ne yaptığınızı gerçek anlamda bilmiyorsanız kullanmanızı önermem).
Başka araçlara göz atmak isterseniz Kaggle’ın bu sene için yaptığı veri bilimcisi anketine bakabilirsiniz.
Bu yazıyı bir iki sene sonra güncellenen araçlarla tekrar yazmayı planlıyorum. Okuduğunuz için teşekkür ederim.
Sorumluluk reddi beyanı: Bu yazı işverenimin (Hugging Face) görüşlerini içermemektedir.
