Açık Yazılım Ağı’nda Geliştirdiğimiz Makine Öğrenmesi Uygulamaları

Yazarlar: Merve Noyan & Alara Dirik
This blog contains the applications we developed for disaster response. You can find the English version here 👉 https://huggingface.co/blog/using-ml-for-disasters
6 Şubat 2023'te Güneydoğu Türkiye’yi vuran 7,7 ve 7,6 büyüklüğündeki depremler, 10 ili etkiledi ve 21 Şubat itibarıyla 42.000'den fazla ölüm ve 120.000'den fazla yaralanmayla sonuçlandı. Depremden saatler Açık Yazılım Ağı Discord sunucusunda kurtarma ekiplerine, depremzedelere ve yardım etmek isteyenlere kaynak olabilecek bir proje geliştirmeye başladık: afetharita.com. Depremin ilk gününde depremzedelerin yardım çağrılarının yazılı şekilde instagram hikayesi ya da tweet olarak paylaştıklarını gözlemledik. Bu verileri otomatik olarak çekip anlamlı hale getirmenin yollarını aradık ve bir yandan zamanla yarışmak zorunda kaldık. Bu blog yazısında oluşturduğumuz uygulamaları ve geliştirme süreçlerinde izlediğimiz yolları anlatacağız.
Discord sunucusuna davet edildiğimde nasıl çalışacağımız ve ne yapacağımız konusunda oldukça fazla kaos vardı. Bilgi almak ve işlemek için makine öğrenimi tabanlı uygulamalar oluşturmak istediğimize ve ayrıca modeller ve verisetleri için bir registry’e ihtiyacımız olduğuna karar verdiğimiz için aşağıdaki Hugging Face organizasyon hesabını açtık. Eğittiğimiz modeller, kişisel veri içermeyen veri setleri ve uygulamalarımız hala bu hesapta bulunuyor.

İlk gün insanların paylaştıkları instagram hikayelerinden ya da twitter’da bu hikaye ekran görüntülerinden bilgi çekip, yapılandırıp, bir veritabanına yazma ihtiyacımız doğdu. Çeşitli açık kaynaklı OCR (optik karakter tanıma) araçlarını denedikten sonra, bu uygulamayı geliştirmek için easyocr ve arayüz için Gradio’yu kullanmaya başladık ekiplerin OCR’den yararlanabilmesi için arayüzden API endpoint’leri açtık. Bu uygulamaya gelen ekran görüntülerinden OCR ile metinleri çekip ardından bu metinlerden aşağıda değineceğim açık kaynaklı kendi eğittiğimiz adres modelini kullanarak adresleri, isimleri ve telefon numaralarını çekip veritabanına yazdık.

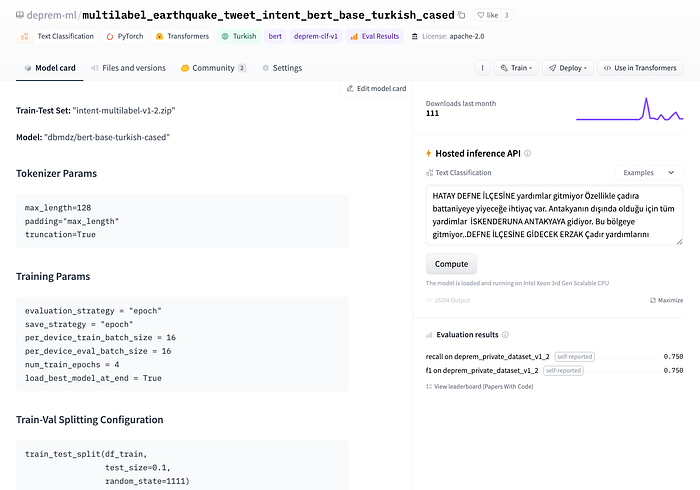
Daha sonra, çeşitli kanallardan yardım çağrısında bulunan depremzedelerin adreslerini ve kişisel bilgilerini (daha sonra anonim hale getirildi) içeren etiketli veri bize verildi. Hem kapalı kaynak modellerin birkaç adımlık yönlendirmesiyle (few-shot learning) hem de transformers kütüphanesiyle kendi adres çekme modelimizi eğiterek denemeye başladık. Bunun için baz model olarak dbmdz/bert-base-turkish-cased kullandık ve ilk adres çıkarma modelini eğitmiş olduk.

Model daha sonra adresleri ayrıştırmak için “afetharita”da kullanıldı. Daha sonra, ayrıştırılan adresler coğrafi kodlama API’sine iletilecek, boylam ve enlem alınacak ve bunları arayüzde gösterilmek üzere dağıtacak olan backend’e gidecekti. Bu modeli inference’a açık şekilde host etmek için Hugging Face’in hazır inference API’sini kullandık. Bu bizi modeli çekip üstüne FastAPI uygulaması yazıp docker görüntüsü oluşturmaktan, her deployment için CI/CD kurmaktan ve sonrasında buluta koymaktan kurtardı.
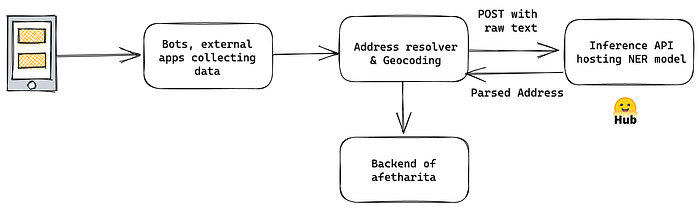
Daha sonra, elimizdeki verilerden depremzedelerin ihtiyaçlarını sınıflandırmak için niyet sınıflandırma modeli eğitmemiz istendi. Her tweet’te birden fazla ihtiyaç vardı. Bu ihtiyaçlara örnek barınak, yiyecek, ya da lojistik olabilir. İlk olarak Hugging Face Hub’da açık kaynaklı NLI modelleri ile zero-shot prompting denemeleri ve OpenAI davinci endpoint’i ile few-shot prompting denemeleri yapmaya başladık. NLI modelleri, aday etiketlerle doğrudan çıkarım yapabildiğimiz ve veri kayması meydana geldikçe etiketleri değiştirebildiğimiz için özellikle kullanışlıydı. Davinci de iyi çalışıyordu, fakat çıktısını backend’e verirken olmayan etiketler uydurduğu için tercih etmedik. Sonrasında elimize etiketli veri geçtiği için, BERT fine-tune etmeye karar verdik. Deneylerimizin performansını model repository’lerindeki model kartının metadata kısmında not ettik, sonrasında lider tablosu oluşturduk.
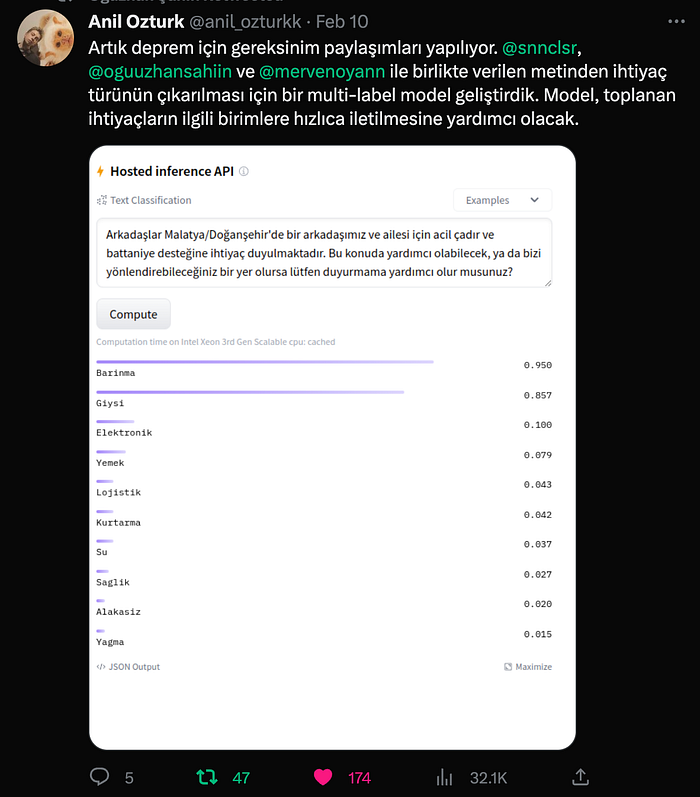
Yanlış negatiflerin olmamasını çok önemsiyorduk (bir ihtiyacın olması fakat olmamış gibi gözükmesi durumu) ve sınıflarda dengesizlik vardı, bu nedenle bir recall ve F1 puanlarının macro average’ı üzerinden bir kıyaslama yaptık.
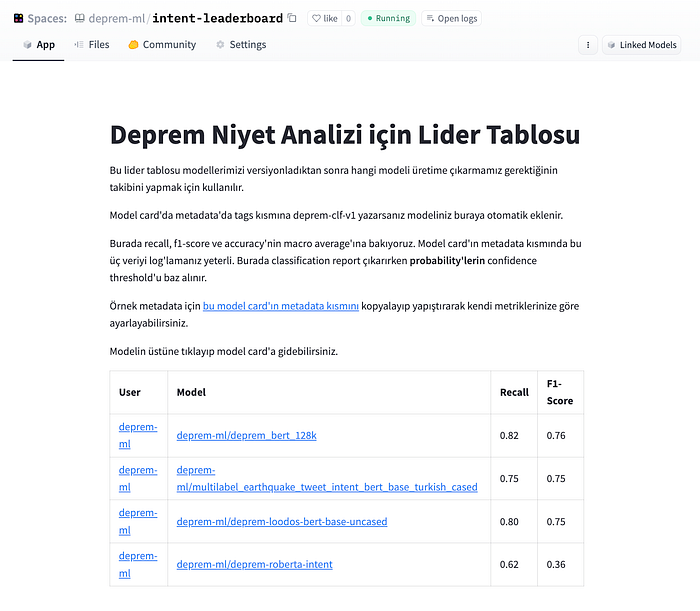
Eğitim setinde sızıntıyı önlemek ve modellerimizi tutarlı bir şekilde kıyaslamak için ayrı bir test seti oluşturduk. Bu problem çok etiketli sınıflandırma olduğu için modelin en iyi performans gösterdiği eşiği bulup not ettik ve üretimde hangi etiketin sepete gireceğini bulmak için bu eşiğe bağlı kaldık.
Veri etiketleyiciler bize daha doğru ve güncel verisetleri sağlamak için çalıştıklarından adres çekme modelimizin değerlendirilmesini crowdsourced hale getirmek istedik. Adres çekme modelini değerlendirmek için, Argilla ve Gradio kullanarak, insanların bir tweet girip çıktıyı doğru/yanlış/belirsiz olarak işaretleyebildiği bir etiketleme arayüzü kurduk.
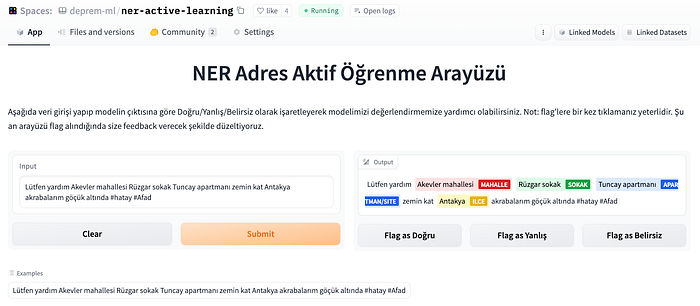
Daha sonra veri setindeki çiftleri çıkardık ve sonraki deneylerimizde modeli değerlendirmek için kullanmaya karar verdik.
Bunun dışında sonradan üretime aldığımız bir projemizde de OpenAI davinci‘yle few-shot denemeler yaparak her tweet’ten daha spesifik ihtiyaçları (bebek bezi, ilaç vb) çekip serbest metin olarak yazdık. Bu modeli FastAPI ile sarıp ardından buluta koyduk.
Adres ve ihtiyaç sınıflandırma modelleri an itibariyle gönüllülerin ve arama kurtarma ekiplerinin hayatta kalanlara ihtiyaçları ulaştırabilmesi için aşağıdaki ısı haritasındaki noktaları oluşturmak için üretimde kullanılıyor.
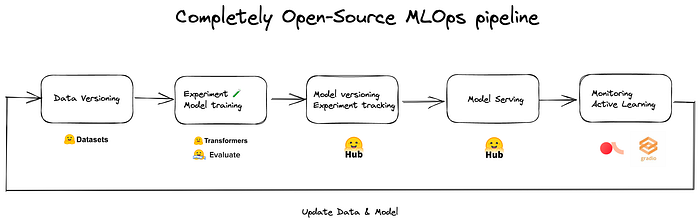
Adres tanıma ve amaç sınıflandırma modelleri için MLOps işlem hattımız aşağıdadır.
Teknik Gözlemler: Hugging Face transformers kullanmak hem davinci’yle few-shot prompting karşılaştırmasında hem de diğer tekniklere karşı yüzde 10–15 civarı doğruluk oranı artışı verdi. transformers’ın başka iyi bir tarafıysa model açık kaynak olduğu için inference API kullanıldığında bir sorun çıkması dahilinde modelin elimizin altında olması ve hızlıca üretime çıkarabilmemizdi. BERT fine-tuning’inde sadece sınıflandırıcı katmanı eğittiğimizden ötürü her eğitim Colab’deki GPU’da yaklaşık 3–4 dakika sürdü, sonrasında modelleri Hugging Face Hub’a attık. Modelin Hub’da olması inference API’nin çalışması için yeterliydi, bu yüzden modeli API haline getirmek için ekstra bir efor sarfetmedik.
Not: Bu uygulamaların arkasında bunları kısa sürede çıkarmak için gece gündüz çalışan onlarca kişi var.
Uzaktan Algılama Uygulamaları
Uzaktan algılama tarafında çalışan takımlar arama kurtarma operasyonlarını yönlendirmek amacıyla binalara ve altyapıya verilen hasarı değerlendirmek için uzaktan algılama uygulamaları üzerinde çalıştı. Depremin ilk 48 saatinde elektriğin ve sabit mobil ağların olmaması, çöken yollarla birleştiğinde, hasarın boyutunun ve nerede yardıma ihtiyaç duyulduğunun değerlendirilmesini son derece zorlaştırdı. Arama kurtarma operasyonları, iletişim ve ulaşımdaki zorluklar nedeniyle yıkılan ve hasar gören binaların yanlış ihbarlarından da büyük ölçüde etkilendi. Bu sorunları ele alma ve gelecekte kullanılabilecek açık kaynak araçları oluşturma çabasıyla, Planet Labs, Maxar ve Copernicus Open Access Hub’dan etkilenen bölgelerin deprem öncesi ve sonrası uydu görüntülerini toplayarak başladık.

İlk yaklaşımımız, “binalar” için tek bir kategoriyle, nesne algılama ve örnek bölümleme için uydu görüntülerini hızlı bir şekilde etiketlemekti. Amaç, aynı bölgeden toplanan deprem öncesi ve sonrası görüntülerde ayakta kalan bina sayılarını karşılaştırarak hasarın boyutunu değerlendirmekti. Modelleri eğitmeyi kolaylaştırmak için 1080x1080 uydu görüntülerini daha küçük 640x640 parçalara kırparak başladık. Ardından, bina tespiti ve bir YOLOv5, YOLOv8 ve EfficientNet modellerinde tespit için ince ayar yaptık. Anlamsal segmentasyon içinse SegFormer fine-tune ettik ve bu uygulamaları Hugging Face Spaces uygulaması olarak dışarıya açtık.
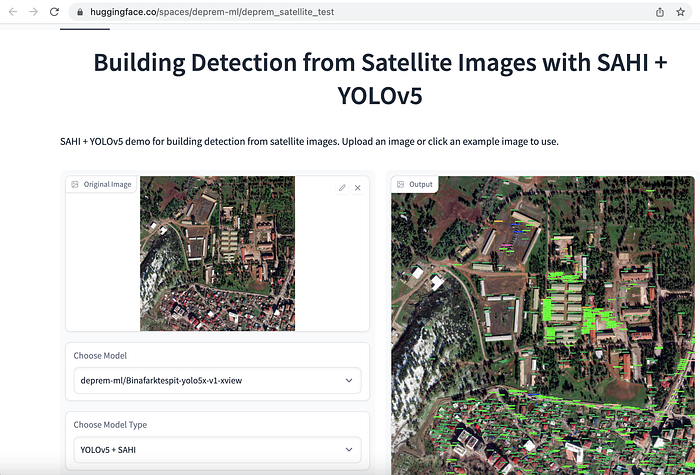
Yine, onlarca kişi etiketleme, veri hazırlama ve eğitim modelleri üzerinde çalıştı. Bireysel gönüllülere ek olarak, Co-One gibi şirketler, uydu verilerini, binalar ve altyapı için hasar yok, yıkıldı, hasarlı, hasarsız tesis gibi daha ayrıntılı açıklamalarla etiketlemek için gönüllü oldu. An itibariyle nihai hedefimiz, gelecekte dünya çapındaki arama ve kurtarma operasyonlarını hızlandırabilecek kapsamlı bir açık kaynak veri seti yayınlamaktır.

